Design-first approach to write APIs
This is the transcript of the talk by Phil Sturgeon presented at Git Commit Show 2020.
About the speaker
Phil Sturgeon builds API Design tools for Stoplight.io. He has written articles and books about pragmatic API design and systems architecture. He has been responsible in part or entirely for projects like the JSON Schema, OpenAPI, The League of Extraordinary Packages, PHP The Right Way, PHP-FIG, CodeIgniter, FuelPHP, PyroCMS, and a bunch of other stuff.
Transcript
My name is Phil sturgeon, wrote a book a while back about APIs. It's now become kind of an online community with a slack group and a whole bunch of blog posts, not just the one book anymore. So there's a lot of content on there if you're interested in API design or API development but if you're new to API design, I can introduce you to the topic.
For the last couple of years, a lot of people have been trying to come up with workflows for their API lifecycle. I'm getting a lot of technologies involved as you hear about swagger and open API and API blueprint and RAML. So which one should you use? People wonder about using annotations in their code or about creating machine-readable open API files by hand or some other way. Should you design first or should you write the code first and then kind of document it later? Are there any visual editors that help with this so you don't have to do a whole bunch of boring stuff by hand? How and when does documentation get involved with this process? and when does mocking get involved in this process? and do you even know what mocking is? and then once we've got these API designs or API descriptions how do we keep them in sync with the code that we've written? Is it possible and how is the first thing to figure out? The first thing I figured out when I was looking at this years ago was swagger or open API v2. As it was renamed I am very old now open API v3 is out, it's great API blueprint and ram have mostly been abandoned. There's not all that much tooling and the tooling that does exist is for slightly older versions. So if you want modern up-to-date stuff, it's pretty simple. You go with open API three, the industry has kind of agreed that this is kind of the go-to standard. When I maintain a website as part of API as you and hey I've got open API tools. It's a community open source project where we just keep track of all the tools that are up to date. So anything that only supports v2, we generally don't put it on there. So there are other lists of tools around but this is the one that they're probably good at. If we don't think they're very good, we don't list them. They look a little bit like this so data validators are one category of tool and you can see whether they support version two or not over there.
So if you're not familiar with open API, this is not an introduction talk to open API. That is a whole other topic but basically, it's YAML or JSON, that is created at some point to describe the contract. The interface of an API, so you can have all sorts of metadata about it and you can put contact information in there. So that people may see this file, know who to talk to, you can list different servers' different paths, give them names, different responses, and if you have JSON and XML differently you can explain those. You can put examples in there which will be used to generate JSON examples and you can have reusable components such as schemas. So you can have some pretty cool stuff that's these schemas will either be one of these and then you reference other files. This is a very quick overview, I'm not trying to teach you open API but just get a little familiar with the idea. That this YAML is describing an API, totally separate from the actual code. This is a vanilla open API by itself. So a lot of people don't want to write all that. Can you imagine sitting there and writing that all out by hand top to bottom? It would take a while, but sometimes I forget how to write it by hand. I'm like, is it content schema responses or content responses schema. I forget, so some people will turn to annotations or dot blocks to solve that problem in java or other languages that have annotations as a first-class feature of the language. This isn't so bad because a lot of the information is inferred from the type system especially if it's a strongly typed language. Then you can have syntax checking to make sure that the path and the methods you're defining are using valid constants and to make sure you're not messing things up but in other languages like PHP. You just have this mess of essentially plain text hiding in the dark blocks and most of your editors won't know. If this is valid or not maybe you can get it, maybe the person that created this specific doc block format has created an extension for vs code, phpstorm, vim, and emacs. But possibly not there are quite a few of these competing formats. Everyone's trying to make them a little bit smaller and a little bit nicer. So they're all subtly different so the chances of you finding one are quite slim. So you're kind of writing this stuff and it just kind of floats above your code and you're just hoping it's correct javascript. There's another one where you literally put the same YAML that you would put into that file and you just kind of float it over the top of your root. It's not I don't find this great the argument that people use is that if it's nearby the code then developers will keep it up to date and that is a lot of ifs and but like theoretically, hopefully, developers will notice this and then do it but they might be in a rush and they might not care or they might not know how or they might update it wrong. So this quote is awesome code comments are just facts waiting to become lies.
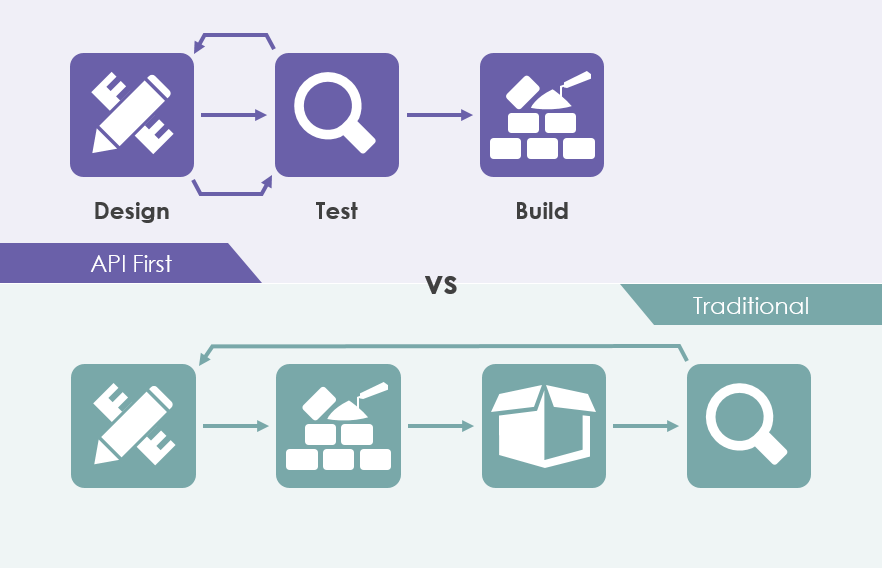
If you're more of a visual learner, it looks a bit more like there's often one thing and does something else. So you have to make sure that doesn't happen or your documentation is lying. This looks complicated but it's the exact design flow that I have seen or the exact um kind of flow where documentation is involved for your open API. People plan it, somehow they chat about it in person. They grab a whiteboard or they grab a napkin or something and just start doodling on it. Then they say that a napkin looks like a great design for our API. Let's start writing the code and so they spend a long time writing all that code, making it work writing tests maybe not bothering yet. They hand that code over a couple of weeks later to the customer to the API consumer to the mobile developers the web people whatever. They ask is any good the customers might then play around with it maybe they spot some bugs but mostly they're trying to give feedback on whether the API will satisfy their needs, whether all of the data they need is there, whether they need to make a hundred different requests to get the information that they need. I'm just trying to find out if the API is useful and then give feedback and then you have to write a bunch more code or change that code and update all the controllers, models and all the tests and that feedback loop takes quite a long time. You can end up being forced to skip some improvements that you would have liked to have made because you have to get it into production on time. But then at some point you deploy it and you think wow that was stressful, let's write some documentation for that pretty soon but then feedback starts to come in, and version 1.1 and version 1.2 or whatever you have to keep adding these improvements fixing these bugs performance issues. Whatever's going on and you get sucked up in maintaining the API that you just deployed and you think we'll get to that documentation. We'll get to that documentation later, don't have time right now. Then a new customer appears and you don't have any documentation to share with them or they just don't exist or they're bad so what ends up happening in my experience is the developers then look at the code to try and figure out how it works because they've forgotten what the contract should be. And the code is a bit confusing, you've been hacking away at it for a while to make it support all this feedback that you've been given. So you end up just creating a new global version. Like version one you forgot how that works, you need to get something working soon. This genuinely happens at large companies. They create versions 2, 3, and 15 just because they don't have time to figure out how that old code worked. Then you're back to planning new functionality. Somehow a new endpoint needs to be made or a new version needs to be made. You just crack out another napkin and get going. So this is how a lot of people have been developing APIs for a long time. Recently a variation of this has popped up which seems to be quite popular. The same stuff you write a bunch of code, then you annotate the code and maybe you do that at first or maybe you wait for feedback or whatever. Maybe you wanna take the code and then share that documentation and get customer feedback on that but you still have this long where you're writing a bunch of code before that. Before you can get the feedback and that's the slow part because changing code takes a lot longer than changing a bit of YAML. Again you deploy the code and deploy the docs. New functionality is requested and you go back to start writing a bunch of code and this is a slightly better variation of code. It's like a blueprint for a house. You could build a house.
You could run around and sketch it but that's not the best use of anyone's time and it's not particularly scientific, safe, or useful. So you are generating a document but if you generate that blueprint before you start doing the work. You then already have this document. So day one after the house is complete if somebody wants to see this document. You already have it, you'd have to run around trying to make an accurate drawing of that thing that already exists. So in API design, first the workflow for several years. This has been what people have been pitching and it's not great. It ends up being a mixture of design first and at some point, you hand over to code first. Very similar to how you design with an open API, you get mocks and docs mocks are like a fake API generated from the metadata that you've created. So people can interact with that mock if they want and they can find out if that works well for them. If they have to make lots of requests and they also get docs. So they don't want to play with the mops. They can look at the documentation to see if it looks like it will solve their problems and then you get customer feedback in a much smaller, more simple feedback loop because you're just tweaking sim YAML. Once it's kind of agreed that is good and you're going to deploy what people then do is either generate a bunch of code. So you then have the second source of truth. You have these old design files that we use for the planning phase but you've kind of moved into code. The code is the source of truth or you like to throw away the open API and use annotations which may be okay. If you don't plan on ever-changing your API but when new functionality is requested you have to follow the code first model. Then pass it over to them for feedback and you have that slower feedback loop. So the workflow that I've been suggesting for quite a while now which is starting to catch on is the same start design with open API mocks and docs customer feedback but then you use those open API files and those machine-readable files. You use them instead of code because it's a contract and it's a machine-readable file. So you can use it to replace things that where you used to write out a whole bunch of code and avoid having those two sources of truth because you just have the one. You can then deploy that code and the documentation is immediately ready and when new functionality is requested, you still have this up-to-date blueprint of what the API looks like, what it does, what all the parameters are, and what all of the validations are. Then you can easily create a new endpoint or a new version or whatever you want to add. You can use the mocks immediately because they're already up to date. AP life cycles are a very big, long, hard topic and I'm not talking about the full life cycle of the API itself but the API design can help out with a lot of these different stages, design mock tests even if it reduces implementation. Then it can help you consume and discover. So there's a lot of these steps that API designs help out with especially if you have those designs very early on. So while I was at my previous employer we were usually in the news if you haven't heard of them before we came up with this whole life cycle for all of the API design files. There's the development cycle, it's kind of the aggregation stage. The development cycle is where you write open APIs and pull requests that can initiate continuous integration which checks that they're good and checks that they're accurate and returns the result. Humans can review it so that API design reviews another concept that is made much easier with API design files.
As the computers and humans agree that it's a good chance for the API, you can merge that to master. Then you know you have some sort of process or some sort of hosted platform. I built my own. Now they exist on open API tools. There's a bunch of them that will look at all your repos and clone them down, take the documentation files and turn them into mock servers and doc servers and generate SDKs and even mirror things to the postman. When I started telling people that we worked 100 APIs there and not everyone was interested in writing documentation for the sake of it but various teams were like “oh I could get a free SDK “ up to date without having to maintain it manually. So different people get excited about different aspects of this workflow and they don't need to love all of it. They just need to like some of it but the problem was most people agreed that writing a whole bunch of YAML by hand was going to be terrible. I understand what he meant but what was created was this and this does not seem particularly easier. It's just a different complicated syntax that people need to learn and that tools need to convert to and from it might be slightly fewer lines but I don't know if it's any more readable than anything else. You can't even see it all on this screen so DSLs are an option. Some look nicer than others but again you have the problem where syntax highlighting might not work and just various things. So while I was still at work, I was wondering where the visual editors are, where are the guises for this. To make things easier and now there's loads of them there didn't use to be a couple of years ago but there are a few competing ones and I work for a company who makes them. Ours looks like this and you can edit all of your paths on the side and update all the information, URLs, and methods. You can just click your way through it and you never really need to look at the open API. You don't need to know what it looks like because you can just work with files in your local file system or you can use the online hosted version. So all sorts of different people including technical writers can work with these files in a very simple way. And even complicated things like data types and all of and any jobs which lots of people that do know open API don't understand um include things like using references to break files down and split spread them across multiple files. So if you've ever considered working with swagger or open API and you've heard and you've seen these like 5000 line YAML files. You don't need to worry about that because you can split things up with ref but again this isn't a tutorial about how to use open API. But a lot of these tools will mix open API description files with markdown files. So you can write tutorials and guides as well as just the very important reference documentation.
Another awesome benefit built into a lot of these editors is the concept of linting if your editor has a lint tool or you're using it in the cli wherever that supports custom rule sets you can enforce API standards and style guides before people start writing because if you link an API that someone's already made and then they output some open API, it might be too late to give them any feedback on that API. This is because it's already code, it's already in production but if you're working with an open API you can have these custom rule sets. I made one here that says every single error, so anything with a four or five response should be one of these two well-known error formats. So we don't want to have custom error formats in our APIs that people might not know how to handle or you can have rules like something you must use kebab case for URLs instead of underscores like the entire company can just discuss decide all of our URLs are going to have underscores. So you can run these linters in your cli for developers to get real-time feedback. You can do it in vs code spectral exists in both cli and vs code. I said some editors have it built in so you can be told how to write better open API as you go which helps developers that don't know anything about open API. To write a better open API without realizing it, so linting is a really useful way to not only improve the quality of the API description but the quality of the underlying API itself. So how on when the mocks get involved um we there's a bunch of tools again on open API tools. You can have local mock servers and hosted mock servers. So here you run your API description and it will just list all the URLs that are available at pets and pet stores and all this stuff and it will run a fake server that you're able to talk to and it will even give you validation messages if you send an invalid request. So the person on the front-end team who is implementing your fake API will get real feedback that they're not quite implementing it correctly so that when you switch out the mock for the rail API. There's much less work to be done and that can increase the parallel parallelization of the front end and the back end both working on their codebases instead of a month for the API to get built and then a month for the front end to get built you can both work on it at the same time. The overall time is one month instead of two. So this gets rid of the waterfall model for API development and there are hosted mock servers too quite often. It's just some project dot sum provider slash endpoint and when you get it gives you a relatively realistic fake of what that real API would use. So at some point, you can just switch out the server and interact with that API documentation. You can just deploy it on s3 some things will read from your git repo. So again list of tools on there and you can have beautiful API reference documentation some of it equivalent to a stripe which is the metric of quality in the API doc world.
I'm just generated for you every time someone merges a pull request and you can even have it generate code samples. So if somebody wants to interact with your API but doesn't know how they can pick their favorite language and just get an example piece of code. How do we keep these things in sync is the main question people normally have. And it's because you don't want to think about this as documentation. Think about it as API descriptions instead of having two sources of truth, you have your code over here telling you what all the validation rules are. Then you have your reference documents or your descriptions saying what all the validation rules are. Again you can just use one for the other you can reuse the API descriptions as code instead of putting all the logic into your model or your controller or your view which some people do for some reason or a service or a contract sometimes contracts to look like this. You write out this whole file that says you know email is required and it should know age to be an integer and all these rejects rules and complications you do this and in javascript, it looks a little bit like this. I think this one's been abandoned. The author wants seven hundred thousand dollars or something to maintain it but this was the nicest one could find. The rest are pretty rough, you write out all this logic which is just recreating stuff you've already done in an open API. This is a close-up of how a request body might look where you are requesting a username email and age. So there's no point in writing this twice. You can just reuse that file as I said a few times. Whenever you have multiple sources of truth you have to put extra effort into making sure that there are no lies in between them. Dread is one example but dread will look at your open API description and then make a request against every single endpoint based on the examples and the data types that you've put in there. But it is generally really hard to work with and one test will affect the state of the other you're talking to a real database in the background. So unlike most test suites, it's kind of tricky to work with my approach for requests is to reuse API descriptions as actual validation in my code. So the API code and the reference documentation are both using the same underlying files and that can be done once you've got your open API.yaml or whatever you've called it in ruby for example you can define a middleware committee as a really good tool for this and just say the schema is open API. That's all the code you had to write and now every time someone requests one of your endpoints. If that endpoint is defined in an open API and there are validation rules and they are breaking those validation rules. They'll simply get an error saying like hey this widget price is meant to be an integer but you send a string or whatever and that massively speeds up how much work you need to do there are loads of these tools in every single language.
So open API.tools will help you find an up-to-date list but it's everywhere and so what that means is if you already have validation code you can delete it and if you're creating a new application from scratch you can you just don't bother writing it in the first place so it's a win-win for everyone even if you already have an API there will be some validations that you need to do for example um like open API can help you find out if that email is unique right somebody might already have that in the database. So you still want to write that five percent of your validation rules are doing something more complex and looking at real data but it can at least confirm and validate that the information being sent is the correct shape and the correct format. That of course only handles requests for responses and some of the middleweights actually will do responses too. But I prefer to use acceptance testing or my existing test suite of any sort to put contract testing in there and again. That's simple if you split your files out so that each one of the models contains each one of the payloads. So request body a response body if you split them, so they're in separate files. Then you can just have one-line assertions. This is our spec example and you get this URL and then I expect the response to match the user model. If it's incorrect your test suite will fail so if somebody updates the documentation in a bad way or somebody updates the code in a bad way, then because you're using the same stuff it's gonna break. You can do the same stuff with client-side validation and I don't quite have enough time to go through this. I should delete these slides out but you can make your models available online so that your front-end users can use those same model definitions and that's another source of truth that you've removed and you can try using any sort of javascript validator. It will give you an error like this right, this isn't a valid email address. You can use that to compute real-looking error messages that the client didn't have to write. So if the length of a name changes then the client doesn't need to update any of their code. It just knows what the correct thing is so this is the situation you can get to by using API design first you not only have this one machine-readable format that works for everything which contains all of your validation rules to use in all different locations but you also had it before you wrote any code which has sped up how much code you need to write. So once again the workflow that I recommend to people is to design it first with an open API using a GUI editor. If you want or any sort of designer that you you like the look of you can all use different designers so long as they all go back into git right uh one person can use vein doesn't matter use mocks and docs to give to your customers to get feedback really early on and keep them in the loop on the feedback and find out what's good and when you have agreed on that um on that contract you can uh use that contract uh you can use those machine readable files i use contract machine readable files and description kind of interchangeably they're the same thing you can use those files to simplify the code creation process not even using code generation just using like runtime validation and uh improve the quality of your test suite and and reduce how much time it spends it takes to create that test suite and you can deploy that code knowing that from day one you have documentation that's completely ready for all of your developers to work with and you can get great documentation that has um SDK generation or or at least basic code examples like curl built in you don't have to make those examples yourself and then. So when somebody comes along and requests a new endpoint or requests changes to existing endpoints backward compatible only then you're ready to go. You already have an up-to-date good quality design to work with so that you can work on that new functionality confidently. People can integrate with that functionality before you write the code.
Now it's time for questions.
Q. What is an open API?
Open API is an API description format that contains metadata about your API. So if you're creating an API you have you know URLs and headers and parameters and body parameters and JSON is coming up or maybe csv going up and multiple different combinations of that. So an open API is a standardized way of describing the entire interface of everything an API could do if you have callbacks and web hooks responding to requests that you make. You can document them or describe them in an open API and JSON schema is another similar compatible standard. So the open API wraps the service layer of all the endpoints and headers and then JSON schema is the kind of the payloads in the bodies of that data. I got it last time I tried using swagger. So I was very excited that yes I will design first and do this but very soon that excitement dreaded off as soon as I entered coding it and then it got more complex. There were more dynamic things that were changing and it seemed to me that there was a gap. I will say there is a learning barrier once you need to learn about this.
Q. Can you share some tips on how we can make getting started with designing first easier any tools apart from the knowledge you shared any tools or anything else that you would like to share?
I'm not meant to kind of promote my products too much but things like stoplight studio with a GUI make it so easy. I struggled myself with some of that stuff um but the idea of the kind of putting an interface on this to make it much easier um I think it is just the most important way I mean I'm working with the open API team to try and write more tutorials because a lot of people look at the specification and that's the only documentation they have for. How open API works are long terse specs and those that use websites don't look at the HTTP specification. They shouldn't need to, so I'm working with them to try and build a bunch more tutorials. So that people can learn how open API works better and there are some resources around. But I think, for now, just using something like stoplight studio or any of the other GUI editors on open API tools. Any of those will help because dynamic requests and responses are hard if you use java or c plus for your API things. Probably aren't that dynamic, you have this field and they will always have this data type but if you're using JavaScript or ruby then like maybe this is a string maybe it's an object maybe this is an array of different combinations of items and the more dynamic the language the more dynamic the API becomes and for a long time swagger. The old version of open API was restricted to basically what would be convenient for java and C++ users and var those other types of strict languages. So with open API 3 and 3.1 which is coming out soon, it's gone a long way to supporting like one of and different data types and maybe this is nullable or not and a lot more things like that. So all of that dynamic stuff has gotten a lot easier in later versions of open API especially if you're using a GUI.
Q. What would you say to developers or the teams who already have APIs in production and now want to start with the open API for their existing and new API they develop further?
You need to develop a workflow that supports everybody. So if new APIs should be designed first like that's the simple part of the equation but how do you catch up with APIs that already exist. If they have annotations, you can export those annotations to the machine-readable file and then delete those annotations and you can delete a bunch of your code and put the server-side validation in there. So that you're using that instead of the code. so you can slowly morph existing APIs towards becoming design first especially if you say like the next version of this API. Well, do you know we're on version 3 right now? We want to build version 4 so we will use v4. We'll make that design first and then when we deprecate the old APIs or the old versions. Then we fixed it so it's a game of catch-up but there are other things you can do like if you have postman collections you can convert those to open API and then you have to fill in a lot of the information because they're not it doesn't store as much information about the payloads.
Q. How would you recommend implementing contract testing and specifically mentioning grad does not seem to support open API 3 for now?
So dread has experimental support for open API 3 and I had to go a bit quick on that slide. I don't honestly recommend tread, it's more of a tool for testing that your documentation seems like it's roughly correct then. It is a tool for like contract testing um contract testing like I mentioned if you google search for JSON schema matches um or just JSON schema validators or open API validators they're kind of interchangeable sometimes if you use those existing tools in your existing test suite you do a bunch of work. You send a post request to it and then you are asserting that the response that comes back is valid compared to the JSON schema file that you have. That's one way of doing it. There are other ways of doing it. There's another tool that we made called prism which is a mock server. I demonstrated that a little bit with a screenshot but it also has a proxy. So you can run a proxy server, you pass it to arguments, you pass it the open API file and the server that you'd like it to go to. Then you make requests to the prism proxy and it will validate that the requests you're sending and the responses that you're receiving match with the open API file so if you send an invalid request or if the server sends you something. It said it shouldn't send, then you'll have an error blow up either in the logs in a header or the payload. So you can't miss it and you can implement this just um mobile developers can run that locally or you can put it in your end-to-end test suite. So that all of your tests when they go through your QA environment whatever you call, they will all blow up if anyone makes a bad request and this replaces the concept of producer contract testing and consumer contract testing by just having in-flight contract testing. So prism proxy or any JSON schema validator or open API validator wrapped up in a test.
Q. One challenge I see in API building API or collaborating over API in the documentation. Let's say instead of just uh diving deep into this someone who wants to cover that challenge of only documenting the API. What are good open-source tools to just do that?
There's a tool called redox um and another one called wider shins they're funny names but there are various tools out there that will just provide documentation and again open API tools has a list of them. There's a lot of tools on there.
Q. Would you like to share any last thoughts with the audience?
I'm currently collating all those blog posts into another entire book so there's a lot of stuff on there that will help you with whatever you're trying to do with APIs. So stick around and ask me questions or find me on Twitter. I'm Phil sturgeon and enjoy the conference.
Thanks for running this awesome!!
Member discussion