Learning from the journey of popular open-source project cURL
This is the transcript of the talk by Daniel Stenberg presented at Git Commit Show 2019.
About the speaker
Daniel has been programming & contributing to open-source since 1985. Daniel is the creator of popular open-source project cURL. cURL is now installed on almost every computer device(4b+) on the earth. In this talk, Daniel shares how he made this open-source project successful.
Transcript
What is cURL
cURL is an open-source command-line tool and the library for transferring data with URLs.
How it all started
It started in 1996. It started out as the first real open-source participation for me(Daniel), I was building an IRC bot. Initially, it was a tiny bot that joins in a chatroom, and it adds some services to the chatroom. One of these days, we needed a currency translation service where we could ask the bot "please translate 100 USD to Swedish crowns" and it would tell you how much that would be with reasonable accuracy. But how do you get a currency rate to the bot? So we needed a little tool for the bot to download the currency rates every night. We found currency rates on an HTTP site. Every night we needed to transfer this HTTP data to the bot. I found a tool called HP for that. It was a few hundred lines of code and I started using it. It wasn't doing everything so I started working on enhancing it. Just to give you a historic perspective, the movie Independence Day came out around that time. I worked on adding more protocols because I found currency rates in other protocols too. And soon I also added upload capabilities for FTP and gopher. At this time, we changed the name of the project to cURL. We released the first cURL version in March 1998 and what's funny is that 1998 is also the year when the term "open source" was coined. Netscape had just recently announced their plans to make their browser open-source, this was the time when there was no Mozilla, there was no Google, there are now a lot of things that we have today that didn't exist back then.
How it grew
We had a lot of open source by then, and I can't say that curl took off immediately because it did not. The first version of it was around 2000 lines of code and sure I shipped it and we started fiddling, and pretty soon, I got help from others. We started iterating and doing new releases and this little slide shows how the "number of lines of code" has developed.
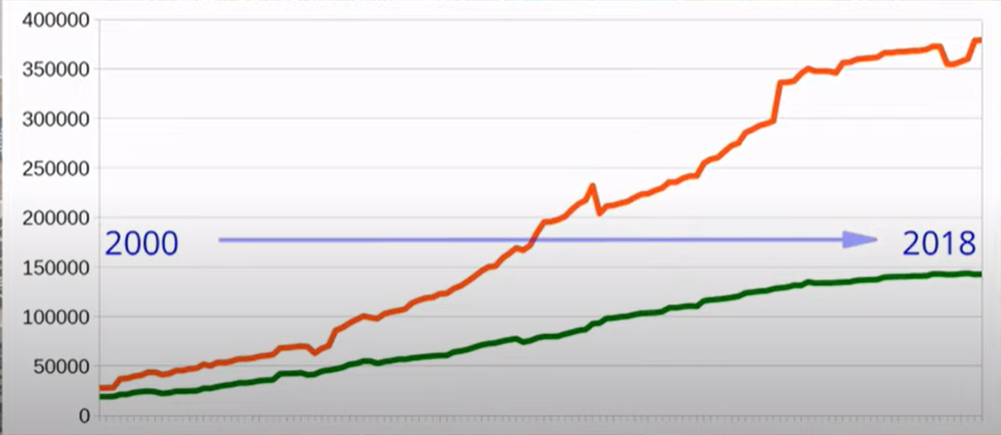
The lower green line here is the one showing the number of lines of code and the red line is showing all the other stuff in the current repository e.g. tests, documentation, and everything. So it has been growing steadily. Although I don't have all the data left since the very beginning still it shows steady growth. Maybe it has leveled out a little bit recently but it keeps growing and growing and growing with time and we have a lot of help from a lot of people over time.
Top 10 cURL users as of 2019
The top ten brands found having cURL references in manuals and documentation are at least 22 car brands. Some very popular in modern cars. There are some 200 million Mac OS machines and cURL is part of Mac OS since 2001. It is bundled in every one of them. Fortnight also uses libcURL and there are a lot of fortnight installations. Television sets, there are somewhere around 400 million TVs in the world that are internet-connected and are using cURLin them. Windows 10 shipped cURL as part of it since version 1803, so 1 billion installations maybe. Mobile phones which by volume then become the devices with the most number of current installations, because there is a cURL installation in virtually every mobile phone in the world. I should say every smartphone at least when it comes to Android and iOS, it's part of iOS chips by the OS. It is being used by some of the most frequently installed applications like YouTube, Instagram, Skype, Spotify. So I think it's a fair assessment to say that almost every smartphone in the world is using curl. So we went from that little thing we did back through the night in the late 90s into the 2000s, 21 years later and it is used in we estimate somewhere around 6 billion installations
Why use cURL
There are a lot of reasons, of course, the internet doesn't follow specs very well. So if you want to do a client that speaks these protocols, with a lot of service on the internet you need to give it time. You need time to polish off all the rough edges and adapt to every quirkiness that is out there and it takes time. cURL now has been that battle-tested, been tried through the years, and sort of learnt with experience. We've been fixing all those problems over time so it's fairly reliable now. We know how to speak these protocols and the code itself is also stable now. It is an open-source and MIT licensed so companies are free to use this code in basically whichever way they want without feeling scared of the open-source license. LibcURL itself provides a simple stable and powerful aid. One of the primary reasons people like curl is also that it's multi-platform and it works the same way on all platforms. So if you switch between platforms you write your application to work on Mac, Windows, Linux, Android, iOS, or whatever you can write it to work the same way. LibcURL is there on all of them and it'll help to do Internet transfers on all of them. One of the benefits of having open source stable API is that the documentation can pretty much remain and just get improved over time. It makes it pretty good over time, pretty complete with a good volume and a lot of examples and everything. The Internet is nowadays full of examples and people have been helping each other with doing things, both using curl as a command line and lib curl with API. Then sure so we have a lot of protocols people like that they can use cURL to do more several protocols. When they have more local needs it's written in C so it should do so. It's reasonably fast, you can footprint. You can switch off a lot of features that you don't need so you can make it smaller and of course, it supports a lot of different TLS back-end so you can also build it with your particular TLS desire. So if you want to use a particular TLS library. You just build your version of cURL with your features. Usually, all these embedded users build their cURL with their own particular needs. It would never have been even close to this if it hadn't been done in open source.
Future of cURL
So usually we're all volunteers here and we're all spare time hackers. So sometimes companies have paid contributors to do feature development and so on but usually we're just people doing it in their spare time because we want to do so. I (Daniel Stenberg) am the lead developer of this and I have been that since as mentioned before. I have created it and released it in 1998. Today a lot of time and effort and patience has gone into it, you just keep on keep on polishing keep on iterating and fix the bugs. Do it again and over time if you just have the patience it can become something that where the action is good Maintaining and developing a project like this is much more than just writing code and doing the commits because there is more. Like them having to do with security issues and have release management updated. Website too is to be taken care of. And also reviewing other people's codes and comment and helping others and trying to mentor them. I also try to blog about cURL the project and what we're doing, what's happening, Then, of course, debug problems and merge the patches when people provide them. It's a lot of work to maintain a project and make it work but of course, it's a lot of fun. I do this for the fun of it, so a lot of people ask me why I do it and how come I never get tired of it. I've been doing this for 21 years. How long I'm going to keep on doing it? Sure it is fun, I can imagine and I don't have any plans. I haven't grown tired of it yet. I still work on it every day. I work on it more now every day than I you have ever before. So yeah this is truly the passion of my life and I don't know at some point in life, I guess it might change but then not right now. People ask me, well isn't it ever done. It never sort of is complete. It truly never gets done because protocols keep evolving, the internet changes and open-source is there. It's not going to die so we just keep on fixing it, we add features well not in every release but surely every other release. We're few people who actually commit dedicated time for some things we want to do in short term but otherwise we just go by the flow, sort of let everyone contribute what they want.
Member discussion