Functional programming skill for effective problem solving in programming

This is the written version of the talk given by Eric Normand at the Git Commit Show 2020. In this talk, he shared insightful questions such as: how to get started with refactoring your code for functional programming, how to deal with dependencies while following a functional programming style, how to simplify, etc. The theme of this conference is - pursuit of mastery.
Full recording of the tech talk - Theory of functional programming
About the Speaker
Eric Normand is the author of the book, Grokking Simplicity, where he gathers functional programming practices from the industry, distills them down, and teaches them to beginners.
What is functional programming?
When we are presented with a choice of technologies between functional programming and object-oriented programming, as you become a master of programming, you would like to look above the two paradigms and choose pieces and parts that fit your problem better. Functional programming and object-oriented programming can co-exist, and you have to master both.
Functional programming is a set of skills rather than a set of features in a programming language. These are skills that you can apply in any language, in any context.
In the book Grokking Simplicity, functional programming is organized in terms of three levels:
- Distinguishing actions, calculations, and data
- Creating and using first-class functions
- Building powerful data models.
The first level is foundational; it is the main definition of functional programming that is used to distinguish these three categories
- Actions
- Calculations
- Data
What are actions, calculations, and data?
Let's say we have some code. In functional programming, we start to subdivide these.
The first distinction we make is that some of these pieces of code depend on when they are called. These are called actions.
We further subdivide those things because there are things that don't depend on when they're called. For example, the code that runs like a sum function does a calculation. That's some kind of computation. String length also computes something.
Then we have data. It's just facts. For example, the number 10. It can't run.

Action is the process of doing something to achieve an aim. So this has some effect on the outside world of your software. They are typically called effects or side-effects, and they depend on when you run them and how many times you run them.
Calculations are computations from inputs to outputs. They always give the same answer. These are also typically known as pure functions. They are eternal, they're outside of time; they always give you the same answer. Another term that is used for them is referentially transparent, meaning they can be replaced by their output and it wouldn't make a difference.
The third category is data. These are facts about events used as a basis for reasoning, discussion, or calculation. It is the easiest one to understand intuitively. It is inert, it doesn't run, and you can serialize it easily. It requires interpretation. You need to run a program to get some meaning out of it.
Let's have a code snippet.
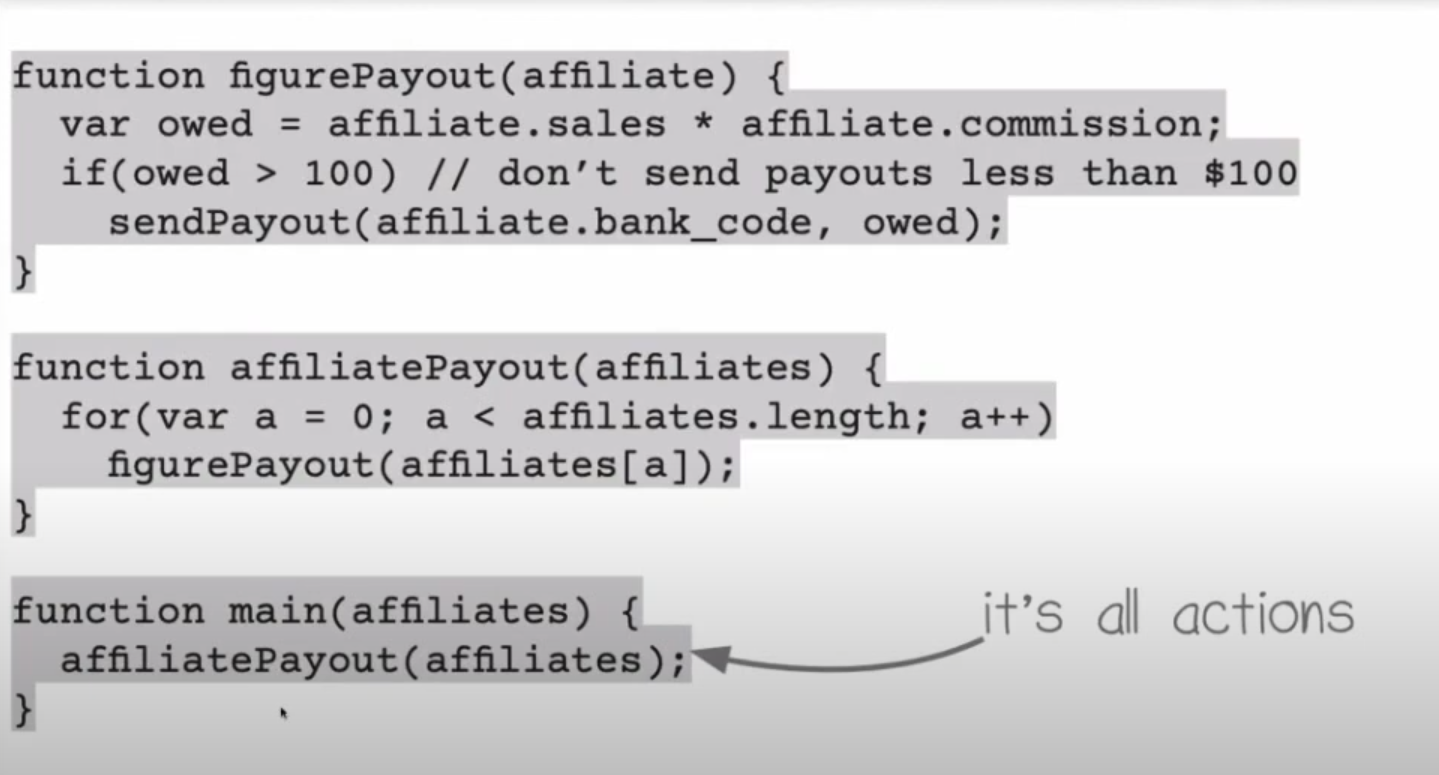
Here the main calls affiliatePayout, affiliatePayout calls figurePayout, and figurePayout is at the top. The figurePayout calls sendPayout. This sends a message to the bank to the bank's API to transfer money into somebody's account. There is this highlighted line, which is the only action, so this is pretty functional, but there is a thing called the spreading rule.
Let's just apply the spreading rule here.
So, here is the action, and by the spreading rule, the whole function figurePayout is an action because it depends on whether you call it or not. If you don't call it, the money doesn't get transferred; if you call it twice, the money gets transferred twice. Since figurePayout isn't an action, then we have to highlight its call in the affiliatePayout function in the middle, but since that one calls an action, the whole function is an action. This is the spreading rule, and since `affiliatePayout` is an action, that means we have to highlight `affiliatePayout` in the main function. And since `affiliatePayout` is an action and main calls it, so main is an action. Therefore, everything in code is an action by the spreading rule.
In functional programming, we try to avoid having actions at the bottom of the call graph. There's going to be some last action and then after that, it's all in the call stack, after that it's all calculations.
Why is this important?
Calculations and data are easy. It doesn't matter when they run; they're easy to test because they can run on a different server. But before you can test them many times, remember that actions depend on how many times they're called, but calculations don't. So you can run it a thousand times to test it. And actions are just inherently harder.
Calculations are easy and you can have a machine to check them. The right actions are difficult, and here most of your bugs are going to be found. This is where the mastery aspect comes in, so that you can direct your attention to the most problematic parts of your code.
So, in level one we learned to manipulate these things and separate calculations from actions in our code using refactoring.
As a master, one tries to make these important distinctions. As you get more and more masterful, you're are able to make finer distinctions. You also become a master of your attention. You can identify problem areas faster because you're able to direct your attention to the important stuff. You're also able to anticipate consequences before they happen.
Now, the second level is where we use first-class functions and higher-order functions. This is all about solving problems and separating concerns.
- First-class values help you abstract
- First-class functions represent the behavior
- Higher-order functions(function that takes fn as argument or returs fn as a result) separates concerns
Note: A first-class citizen (also type, object, entity, or value) is an entity which supports all the operations generally available to other entities. These operations typically include being passed as an argument, returned from a function, and assigned to a variable. (Reference: Wikipedia)
In terms of mastery, this is where you will get finer grain control because a first-class value lets you think more abstractly and in a generalized way instead of being specific. By separating these concerns, you will get a much higher resolution perception of what's going on.
So let's look at a code smell called the implicit argument in function name.

The function at the top is called setPriceByName and it takes a shopping cart, looks up an item in the shopping cart by the name, and then changes the price. It sets the price based on the argument. Then there are two similar functions called setQuantityByName and setDiscountByName. The codes are almost identical. The only difference is that they set the quantity and the discount.
Let's fix this code smell by refactoring to express implicit argument

The highlighted yellow stuff at the top of the field appears in the name of the function. It's a kind of implicit argument that the field name that we're using in the object set is named by the function itself.
We will do refactoring, which is taking this implicit argument that is part of the function name and making it an explicit argument. This code at the top becomes the code at the bottom that we call setFieldByName because now it's generic and we're adding this argument called field and that's what gets passed into the object set. So, instead of having setPriceByName, setQuantityByName, and setDiscountByName functions, you only have setFieldByName.
This is a way of making the field a first-class value. As part of the function name, it's not first class, but now it's just a string and you have a whole language to help you manipulate it.
The next refactoring is called replace the body with a callback

So we have these two for loops and they're doing two different things. The first one is cooking and eating the food. There is an array of foods that you loop through and cook and eat. At the bottom, we have an array of dishes. Here you have all your dishes. When you're done, you've got to wash them, dry them, and put them away.
Notice that they have a lot in common.
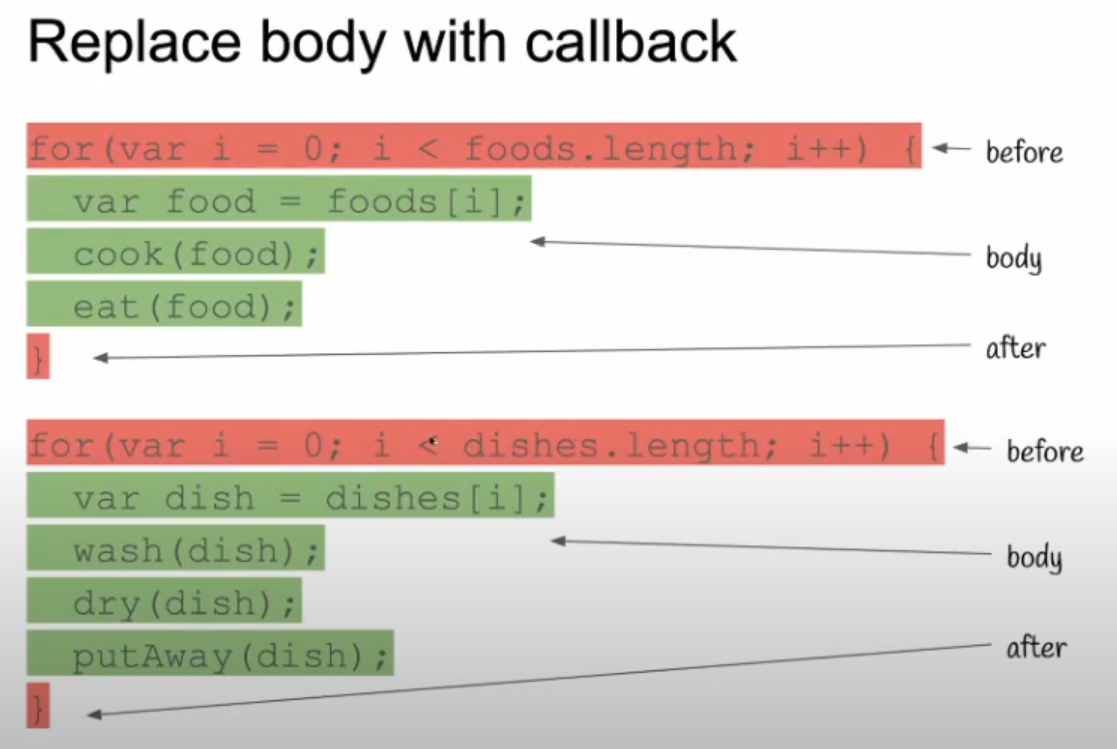
This red part at the top is very much like the red part in the second for loop. You are initializing a variable to zero and comparing it to the length of an array and iterating the array. The difference is what goes inside the loop. So how do you remove the duplication of this code?
This refactoring lets you replace the body, which is this green part, with a function, and then that function gets passed to another function. You will make a new function that takes the array and the function that represents the body, and then you can loop through.

So now let's move on to level three. This is all about building powerful data models. The fundamentals are in level one, which is the most important, and as we get more skilled, we'll be able to use them. We'll master those things.
- Modeling facts with general-purpose data
- The closure property lets us create complex expressions.
So, we're going to be modeling facts with general-purpose data. This gives us models with very high fidelity, meaning we'll be taking some real-world things and translate them into a data representation that captures all the important stuff.
The next thing is that we're going to be able to define operations on this data that lets us use the closure property. It allows us to express way more than we could with a regular API.
For example, let's look at this code snippet.

At the top right, there is a pepperoni pizza recipe. It's got the ingredients and how to assemble them. We've used the properties of JSON to model this recipe and keep the same structure as in the recipe. Ingredients and preparation don't need to be in any particular order, so we used objects there, whereas the assembly needs to be in order, so we put them in an array. We can make a bunch of operations and they will take ingredient lists, operate on them, generate them, and return them.
Closure property lets us nest our calculations and make arbitrary complex expressions using formulas and operations, and we can imagine an infinite number of expressions. We can make an infinite number of these and precisely target any question or calculation. When you're building out these APIs, it is this ability to make an infinite number of expressions that become really helpful.
For more such talks, attend Git Commit Show live. The next season is coming soon.

![OS for Devs - Ubuntu vs nixOS vs macOS [Developers Roundtable]](/content/images/size/w750/2023/12/IMG_20231216_204048_584.jpg)



Member discussion