How we built an engine that understands shallow work vs deep work

Hi folks, I m Nischey, Co-Founder and CTO of Invide
Invide is a community of 15000 remote developers est. 2016, we run various free growth programs and conferences notably Git Commit Show for devs from remote areasToday I will provide you a sneak-peak through the technology implemented at Invide for Deep Work analytics. Invide has launched a product called Developer Diary, which is used for encouraging deep work in software engineering and cutting down distractions. Developer Diary also provides you detailed analytics on what areas you worked on, how much time was deep work time, how much time was idle, etc. But, first
What is Deep Work?
“Deep Work” is a term popularized by Prof. Cal Newport in his book “Deep Work - Rules for Focused Success in a Distracted World. An excerpt from his book
“Deep work is the ability to focus without distraction on a cognitively demanding task. It’s a skill that allows you to quickly master complicated information and produce better results in less time. Deep work will make you better at what you do and provide a sense of true fulfillment that comes from craftsmanship. In short, deep work is like a superpower in our increasingly competitive 21st-century economy. And yet, most people have lost the ability to go deep—spending their days instead in a frantic blur of e-mail and social media, not even realizing there’s a better way.”
How does Invide distinguish between Deep Work vs Shallow Work?
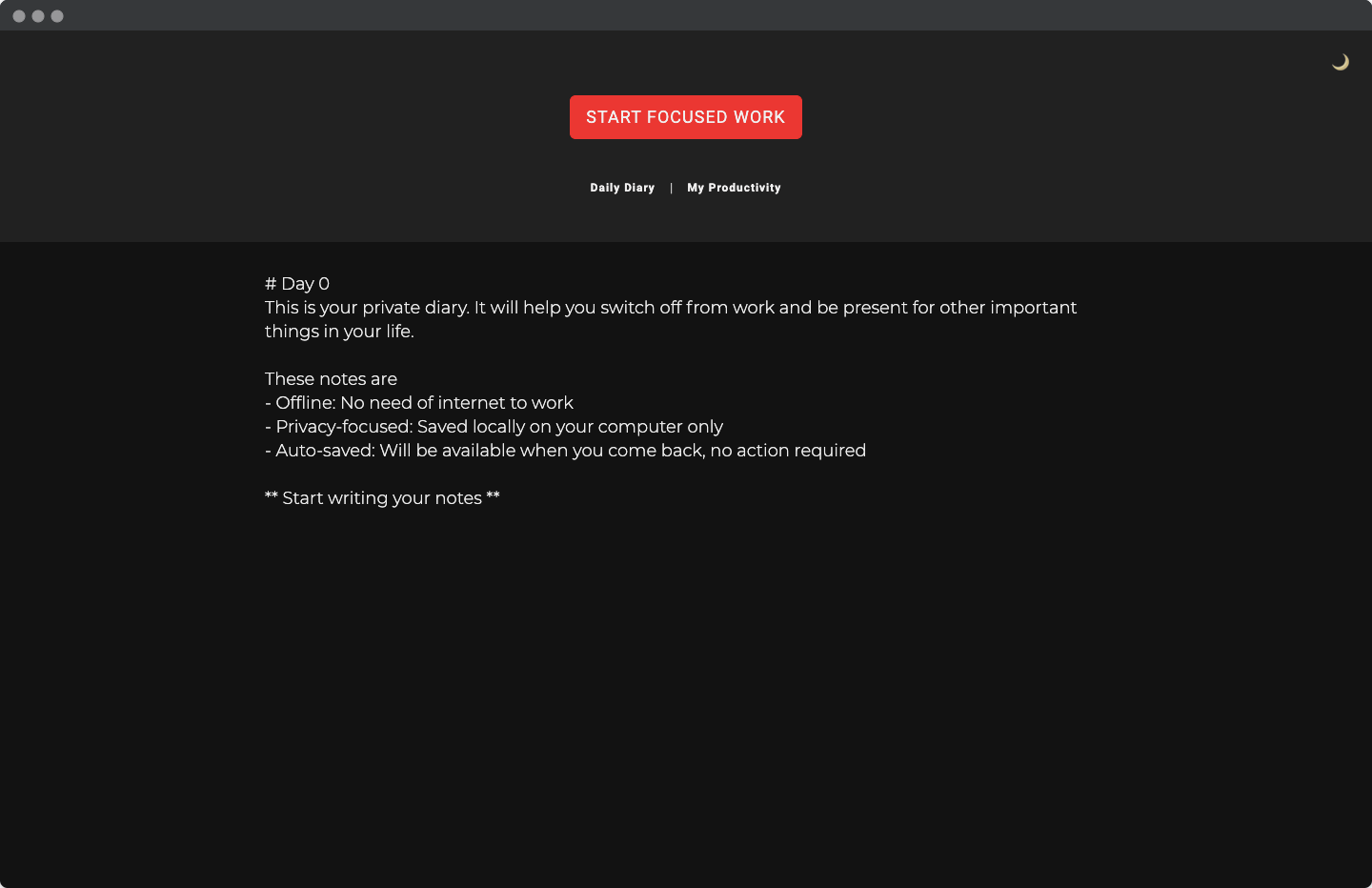
Developer Diary is a desktop app that provides a feature of Deep Work analytics. When you use this feature(by clicking "start focused work" and permitting it to analyze work), it collects basic information about a work session: the title of the currently open window and the application name. To ensure the privacy of the user, it does not collect any other data. By design, it proactively restricts any access to other data that would be privacy intrusive even if it would have made the analysis work easier. The challenge is
“With just window titles and application name, we have to compute the category of the work accurately(coding, documentation, coding research, personal, etc.), the probability that it's part of deep work, etc. Determining this requires an understanding of the semantics of the language. For example, if I'm watching “Java tutorial - Youtube”, most likely I m working on coding related research and it should be part of productive work, whereas if I'm watching a politics related meme video, it should be marked as personal work.
We use natural language processing (NLP) to understand the semantics and a context-aware rolling window approach to improve our predictions. Let me describe the two parts of the engine in detail below:
1. Natural Language Processing (NLP) to compute semantic tags
NLP is a hot field. NLP started with a simple bag of words approach where every word would have a contribution to a specific class, For example, the words happy, bright, amazing, etc would imply the sentence is a positive one, whereas the words sad, low, filthy, etc would imply the sentence is a negative one. The simple bag of words approach is ok when we have a small number of classes and there are no complicated sentence formations involving multiple conflicting word classes.
In our case, we don't have just two classes, we have about 30 different fine-grained classes and this list is ever-growing. Eg python, java, etc. The sentences in the real world are much more complex and cannot be effectively solved using a simple bag of words approach. Eg.
“How to recognize images of Barack Obama using convolutional neural networks?”
The above sentence has the following notable keywords:
Barack Obama - represents class “politics”
Convolutional Neural Networks - represents class “data science”
Now if we follow a simple bag of words approach we understand that there is a 1:1 tie, so we won't be able to confidently determine the class. Also collating an exhaustive list of keywords representing a particular class is a tedious job.
So what can be done?
Word embeddings to the rescue !!!
Word embedding is one of the most popular representations of document vocabulary. It is capable of capturing the context of a word in a document, semantic and syntactic similarity, relation with other words, etc. It's similar to representing a word as a dense vector of say 100 dimensions and in cosine space, similar words would be closer to each other.
Word2Vec is one of the most popular techniques to learn word embeddings using a shallow neural network. It was developed by Tomas Mikolov in 2013 at Google.
Without getting into its mathematics, I would like to demonstrate high-level idea of this approach.
This is a deep learning based approach where we are going to predict a word based on context words.
- Convert words to vector
- Create training data (input, output pair)
- Train using CBOW model
1. Convert words to vector
In case you don't have know about deep learning yet, deep learning is based on dense neural networks which needs numeric data.
As we cannot put textual content in neural network,
How do we represent words as numeric?
Let's say we have 10000 words in our dictionary. Each word here can be represented as a one hot vector, which looks as follows
Python = [1,0,0,0……]
Java = [0,1,0,0,......]How to construct this one hot vector for a word?
So as we assumed earlier that our dictionary has 10000 words, so Every word can be mapped to a specific index of this dictionary array. Let's say the index of the this word in the dictionary is i. Then the one hot vector for this word is an array of length equal to size of dictionary where ith index is 1 and others are 0.
Example: if python is available at index 0, then it's one hot vector is
Python = [1,0,0,0……(9999 times)]
Now that we have converted words to their numeric form, let's move on to next step
2. Create training data (input, output pair)
How do we construct training data for word embeddings?
We have a huge corpus of text, checkout some example text from the data below
I want to learn Python
I want to learn JavaNow we will create training pairs similar to following for above example text
// Training pair 1
Input: I want to learn
Output: Python
// Training pair 2
Input: I want to learn
Output: JavaLet's move on to next step to train with this data
3. Train using CBOW model
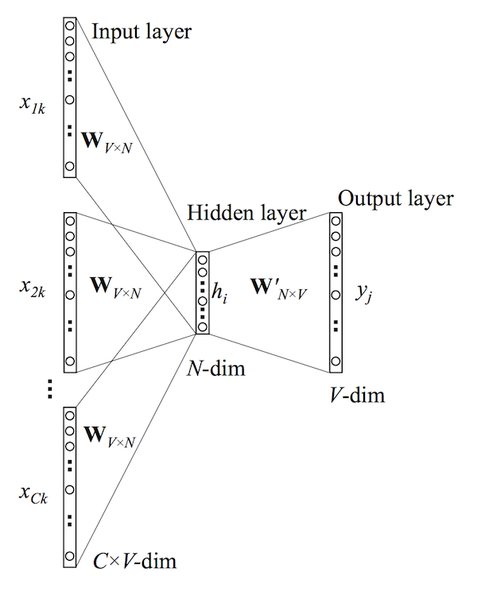
In this model, we create a neural network where both inputs are a set of 10000 dimensions one hot encoding of input and output words of dimension 10000 and there is a hidden layer of dense 100 dimensions.
If it successfully trains itself, for the input examples we showed in step 2("I want to learn"), it will output python and java with nearly equal probability as both occurred in a similar context("I want to learn") in general English text.
Now the inner vector of 100 dimensions can be used as a dense representation of the word. And we have cosine space where every word from vocab can be plotted. Similar words like java and python would be closer to each other in this cosine space.
This dense vector corresponding to the word represents the semantic meaning as similar concepts are closer to each other in cosine space.

This model has been trained on the entire English corpus. This approach does not need manual tagging. This is better than a "bag of words" approach because it would have been impossible to get an exhaustive list of words representing a particular class.
Sentence embeddings
Similar to word embeddings described above we have sentence embeddings that provide a dense representation of the entire sentence, instead of just a word. In such a case the following sentences would become similar to each other in cosine space
“I m fine” ~= “I m doing great”
The available model architectures for getting sentence embeddings include Doc2Vec, BERT, Universal Sentence Encoder, etc
2. Context-Aware rolling window analytics
Now that we have a foundational understanding of individual activity types, we need to move towards the final goal of measuring deep work.
Deep work is focused, continuous work that is meaningful and rare
One challenge here is that, considering individual activity types without being aware of the context might give data on which making decisions like a human is not practical, consider this case
"This morning, I was working on a complex coding problem for ~1 hr(productive activities), I was not getting the right ideas and then I started a youtube video(entertainment) to lighten the mood. Only the next moment, I got an idea and started coding on this new idea. Only after a couple of mins, I came back to the video again and then again got back to work and it went on for next 30 mins until I finished the work and called it a day."
Our activity tagging shows that 10 mins out of that 1.5 hr period were non-work activities. While I was engaged with the work during these 10 mins, and those 10 mins helped me finish the problem, should we subtract those 10 mins from productive work time? Or should we look at the bigger picture and count those 10 mins activities as productive although the individual activity data tells a different story?
Let's take another counter-example
"I was watching a movie last weekend and I got an email. So I paused the movie and replied to the email. It took me about 10 mins to read the email and respond. I got back to the movie again. In those 2 hrs of watching a movie, should those 10 mins of the email be counted as productive or shall we ignore it simply as being an outlier or may call it a distraction in our break?"
That's where we defined the idea of productivity sprint
A productivity sprint is a continuous period that can practically be qualified as productive work or a break
A productive work sprint is a continuous productive period. This continuous work is meaningful and helps you move 1 step closer towards your goal. Productive work sprint time ignores comparatively small chunks of "seemingly unproductive" activities in between
e.g. you worked 3 hrs straight with a couple of short coffee breaks -> the productive sprint time = 3 hrs (ignored those coffee breaks)
Similarly, Break sprint is a continuous break with little or no productive activities in between
Productivity sprint data helps you make important decisions like a human. Productivity sprint accepts the limitations of our brain focus. At the same time, it inspires us to improve our ability to build focus pragmatically. This is how the final summary of key metrics looks like
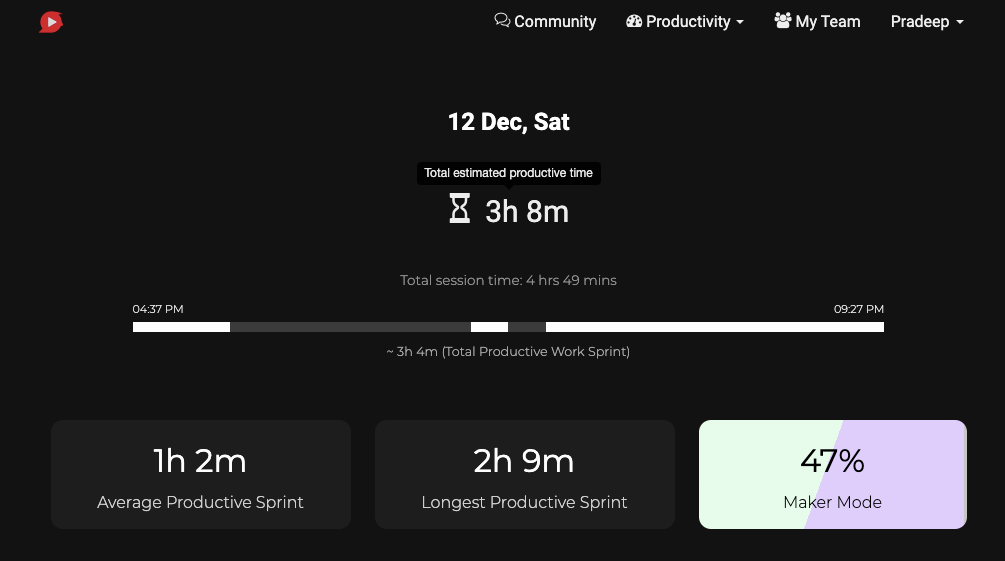
This analysis is done over the nearest rolling windows of the period (instead of the fixed period) to address the continuous context of the data. An activity can be part of deep work or not, it depends on the context(not just the individual activity). You may audit the accuracy of the results in your dashboard by looking at the raw data and the corresponding analytics.
We're working on enabling users to extend our work by writing small snippets of code on top of existing analytics features and make it more personalised and more meaningful for themselves. As we believe
Everyone is unique and will do wonders if they reach their full potential.
Download the app to get started
Work with us
Note: In part 2 of this article, we will cover more on how we optimized multiple parameters involved that led to accuracy after endless testing.



Member discussion